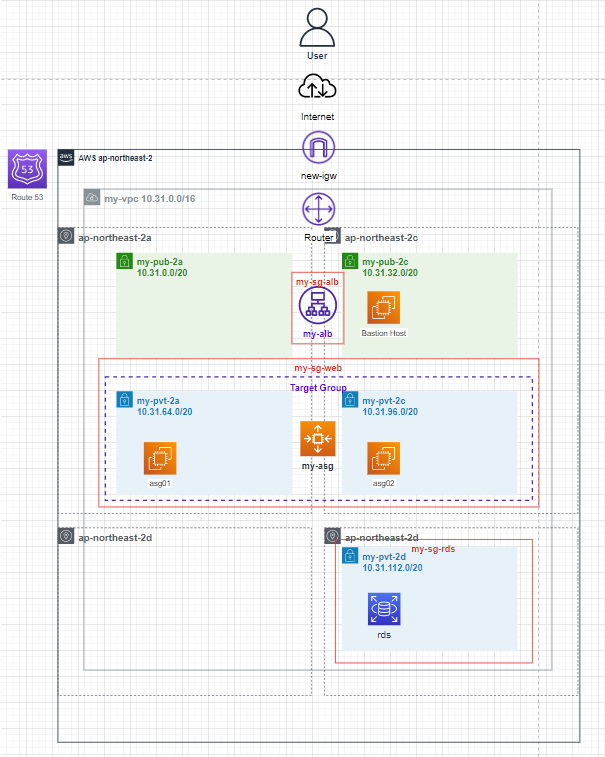
구축할 네트워크 망도
Auto Scaling
AutoScaling이란?
애플리케이션의 로드를 처리할 수 있는 정확한 수의 인스턴스를 보유하도록 보장할 수 있다.
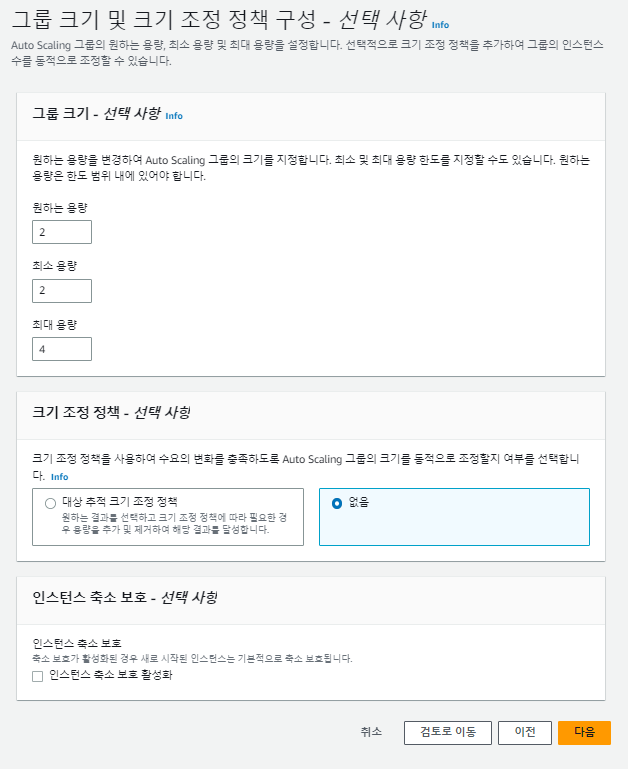
Auto Scaling 그룹이라는 인스턴스 모음을 생성한다. 각 Auto Scaling 그룹의 최소 인스턴스 수를 지정할 수 있으며, Auto Scaling에서는 그룹의 크기가 이 값 아래로 내려가지 않는다.
각 Auto Scaling 그룹의 최대 인스턴스 수를 지정할 수 있으며, Auto Scaling에서는 그룹의 크기가 이 값을 넘지 않는다.
원하는 용량을 지정한 경우 그룹을 생성한 다음에는 언제든지 Auto Scaling에서 해당 그룹에서 이만큼의 인스턴스를 보유할 수 있다.
Cloud Watch를 통해 CPU의 사용률을 감시하고, 설정한 임계값을 넘기면 알람을 울린다. 그 후, Auto Scaling을 통해 새로운 인스턴스를 생성하는 하여 ALB 헬스 체크를 정상으로 판단하면 해당 인스턴스를 포워딩하는 방식으로 작동한다. 이를 Scale Out(수평적 확장)이라 한다.
반대로, 여유가 있는 경우 인스턴스를 지워나가는 것을 Scale In(수평적 축소)라고 한다. 하지만, 다 지우는 것은 불가능하고, 최소값(Minimum) 밑으로는 지우지 못한다.
다른 방법으로, 인스턴스가 아닌 CPU나 메모리 등, 하드웨어의 스펙을 올려줄 수도 있는데, 이를 Scale UP(수직적 확장)이라 한다.
반대로, 하드웨어 스펙들을 낮추는 것을 Scale Down(수직적 축소)라고 한다.
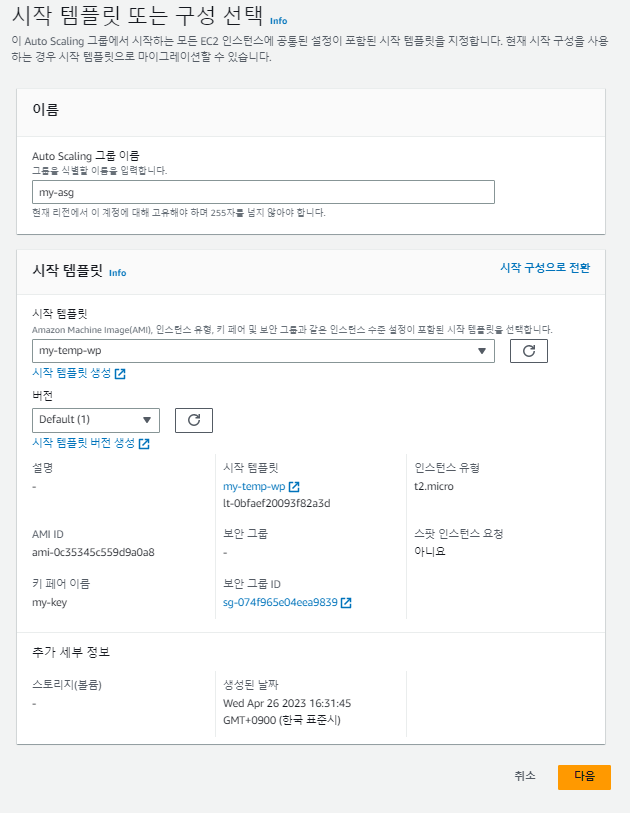
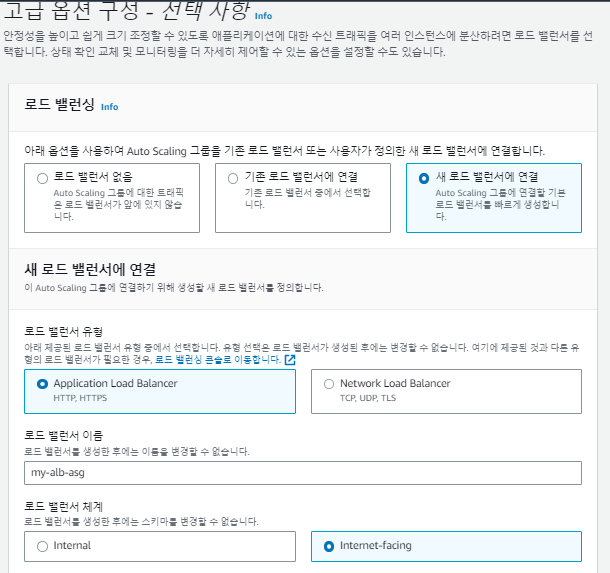
오토 스케일링 생성
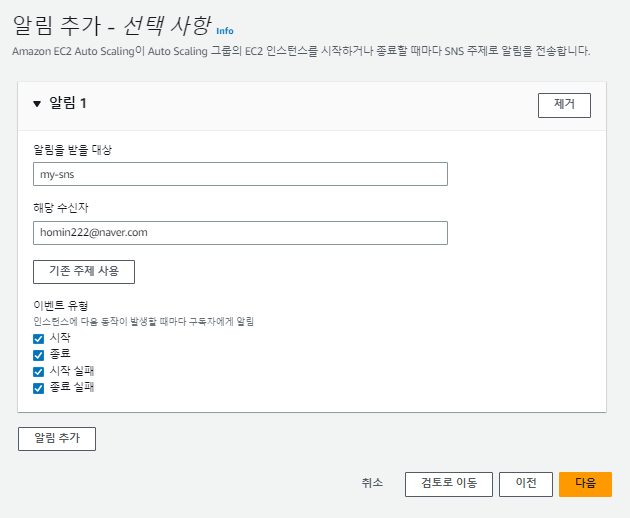
해당 메일로 메일이 오는데, 해당 메일에서 수락을 해야 알림이 정상적으로 온다.
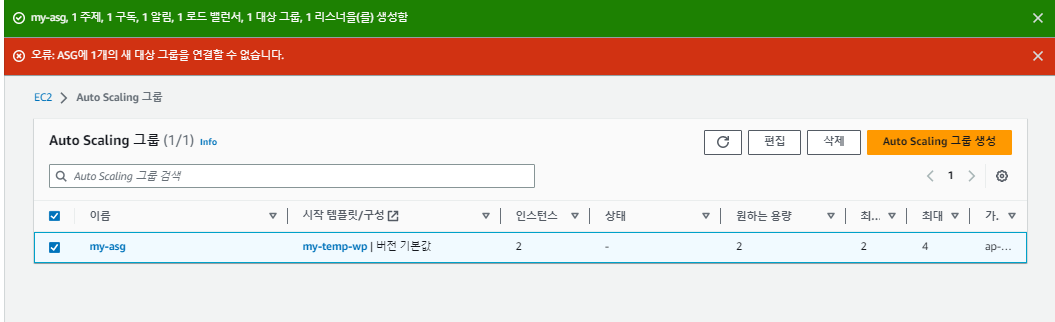
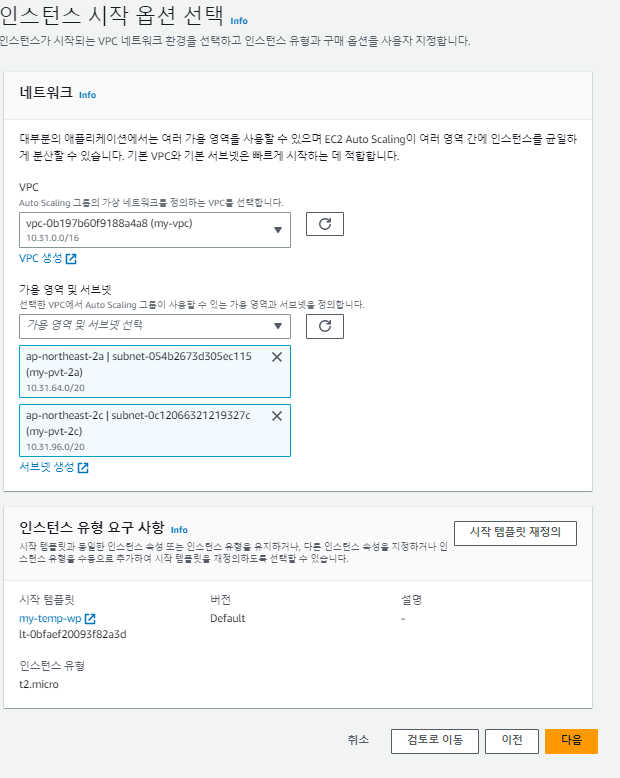
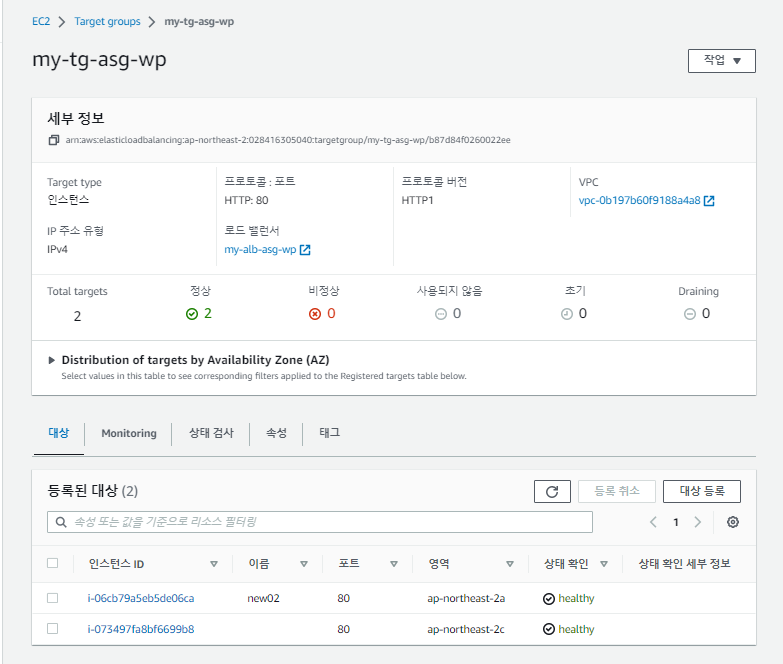
하지만, 위의 사진에서 오류가 나타났듯이, 대상 그룹에서 대상을 지정 못했으므로 대상을 지정해야한다.
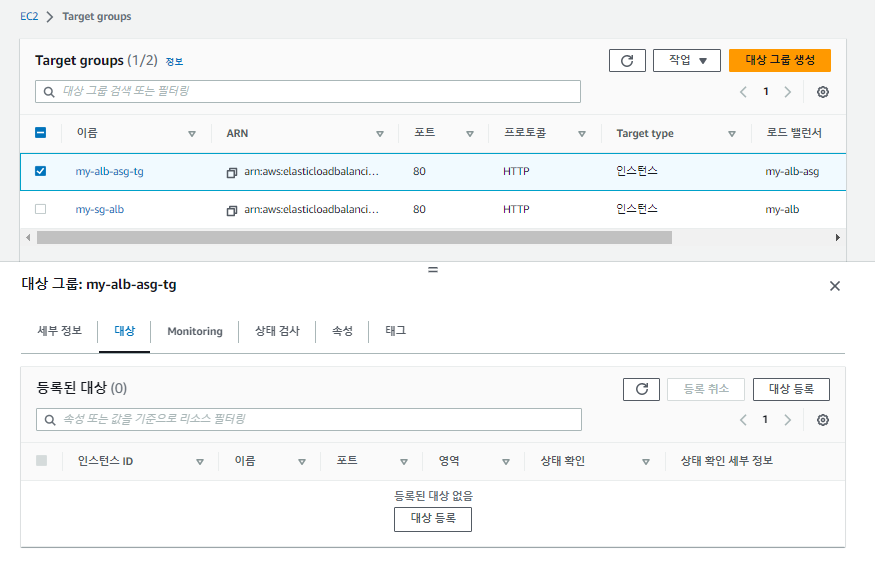
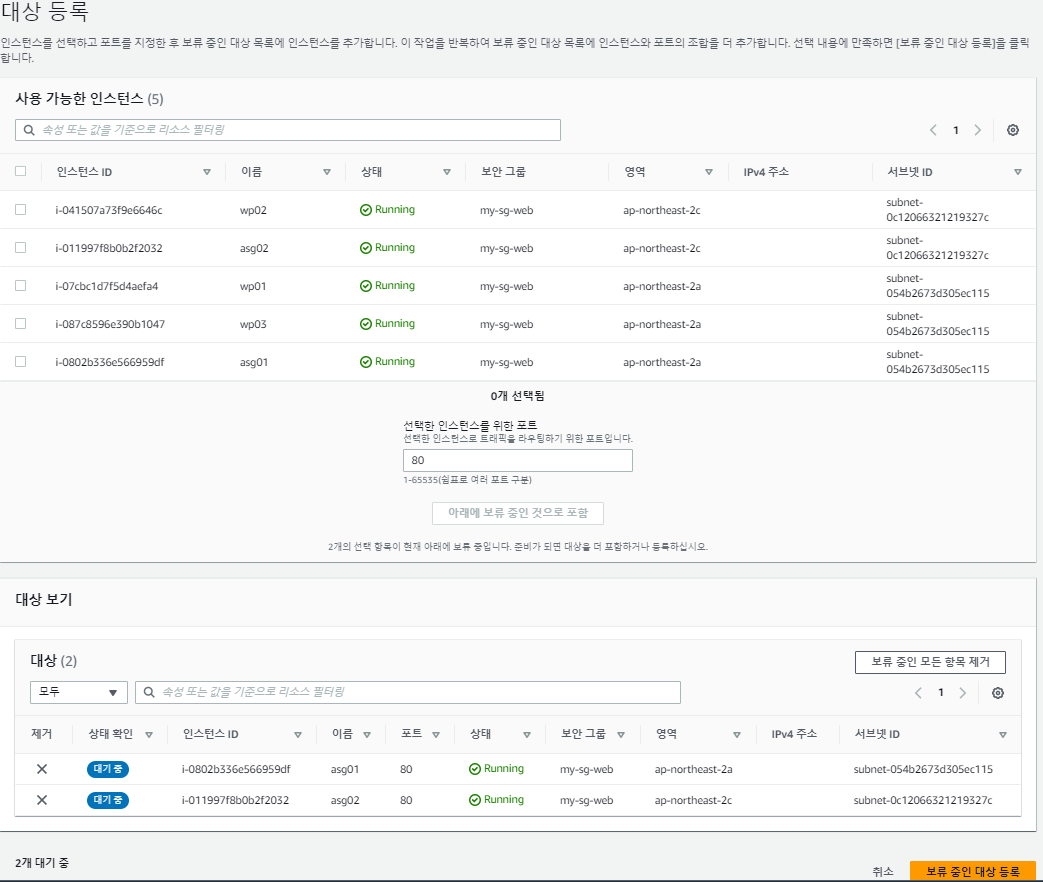
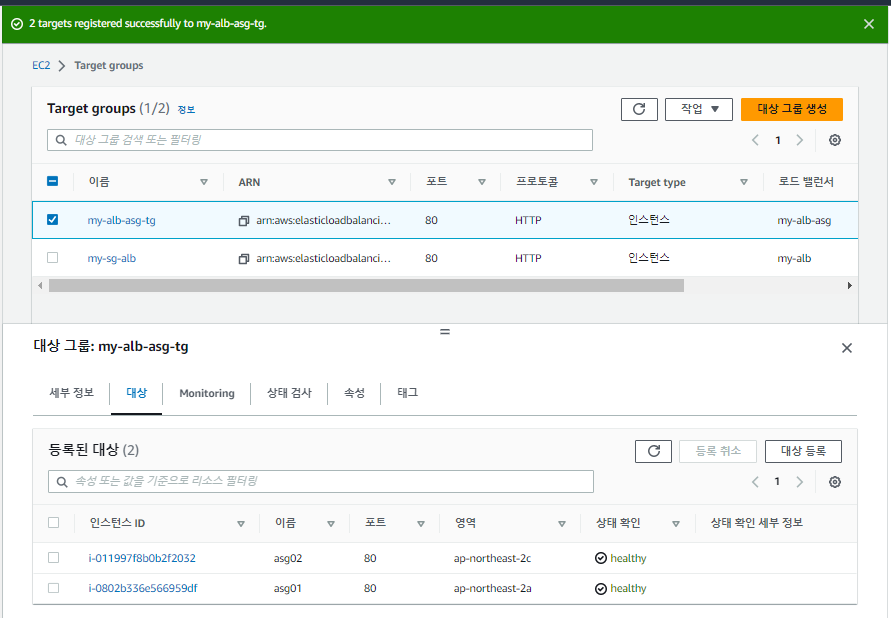
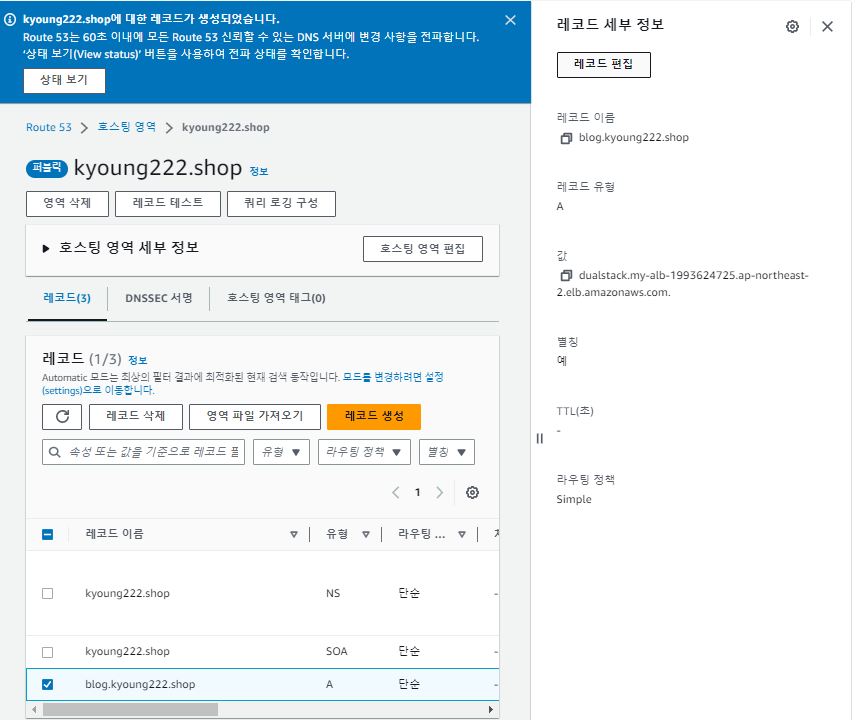
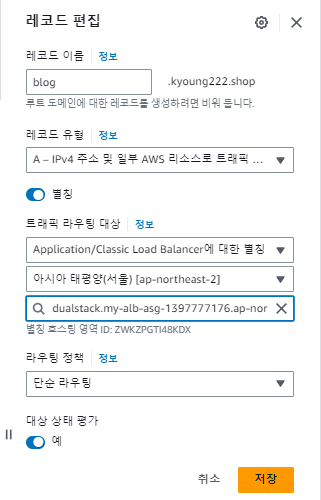
다시 돌아와서, 템플릿을 사용하다보니 의도치 않은 보안 그룹을 사용 중이므로 보안 그룹을 수정해준다.
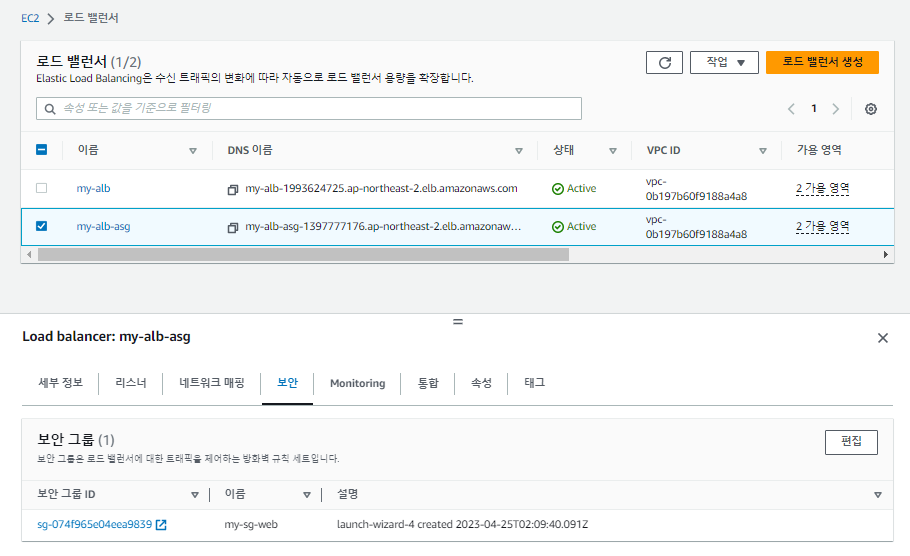
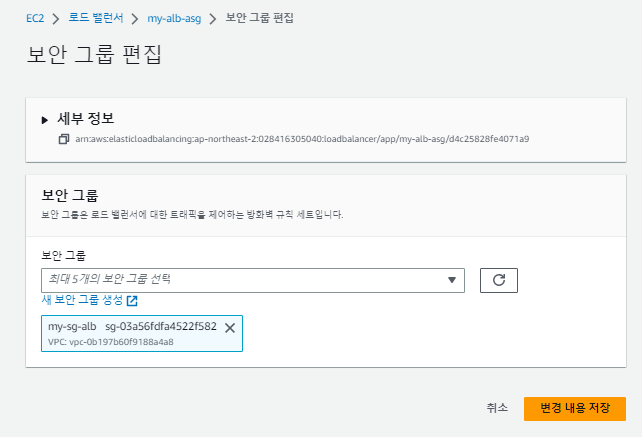
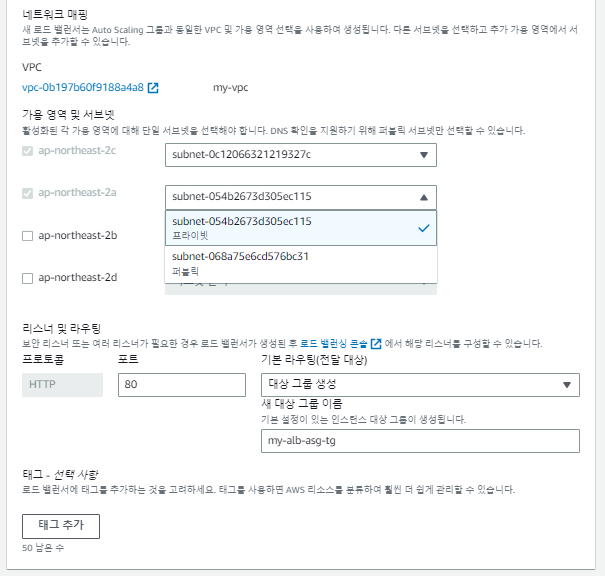
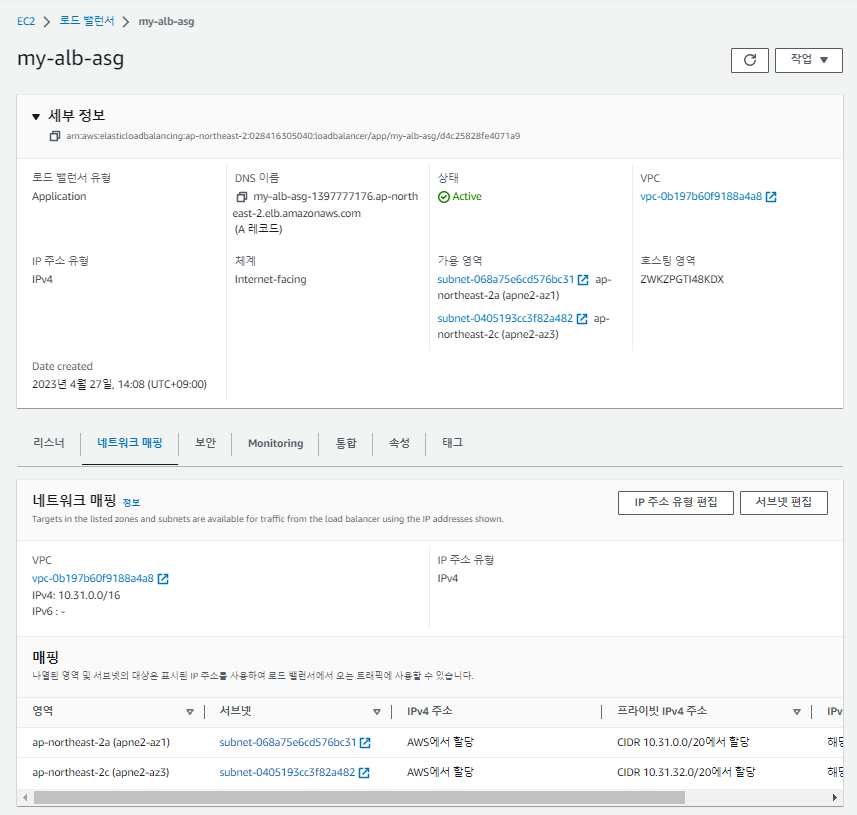
서브넷 부분도 템플릿을 사용해서 'public'이 아닌 'private로 되어있다. 이를 수정해준다.
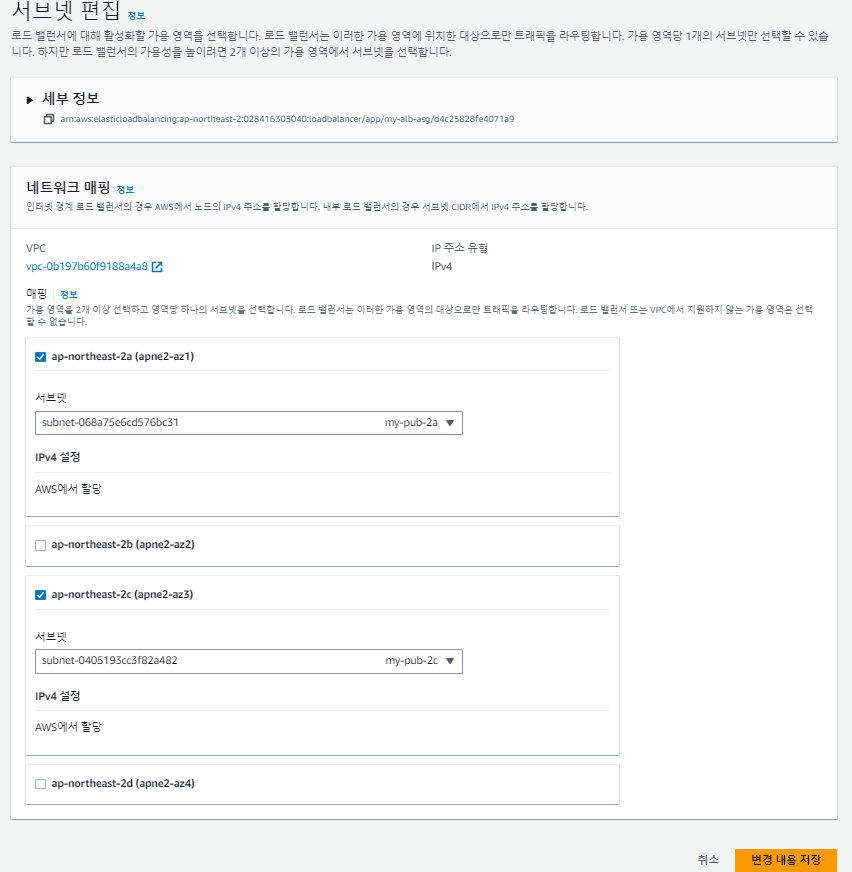
오토 스케일링 (ScaleOut) 생성
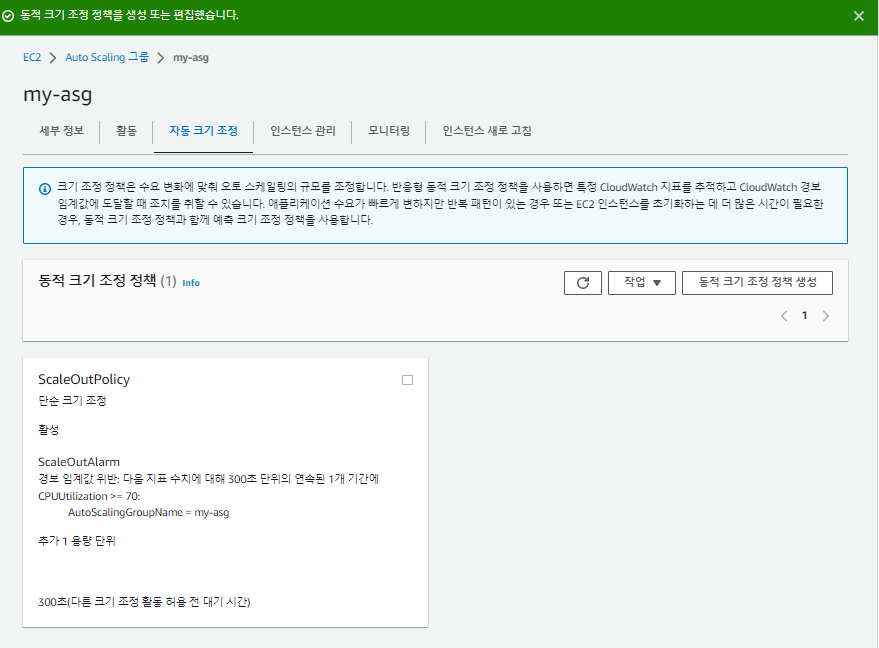
이제 CPU 사용률이 증가하면 인스턴스를 늘릴 오토 스케일링(ScaleOut)을 생성한다.
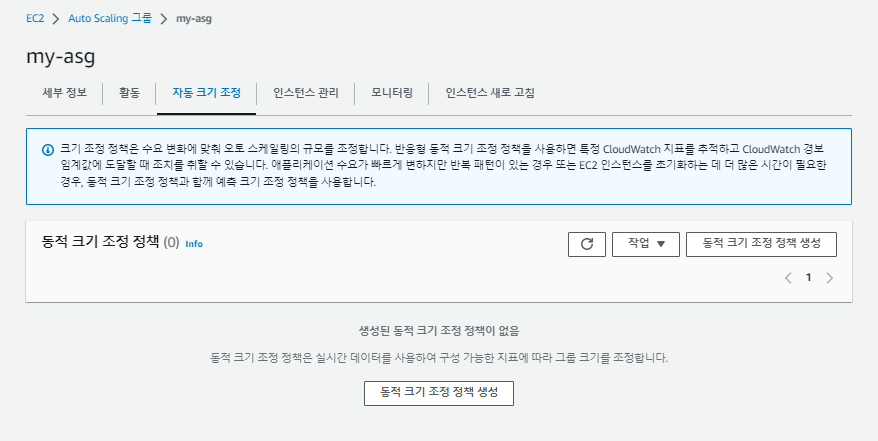
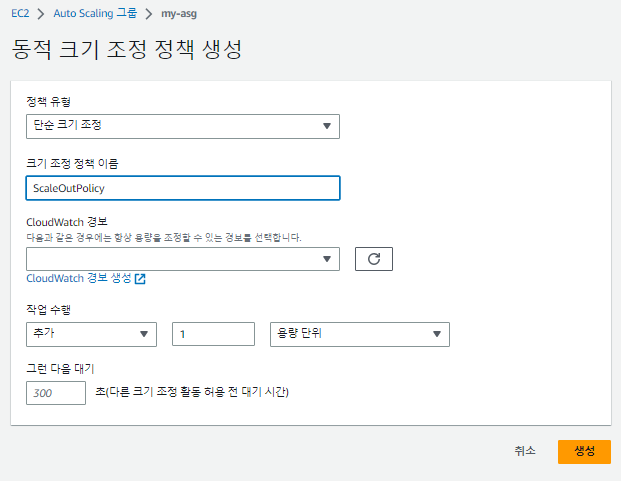
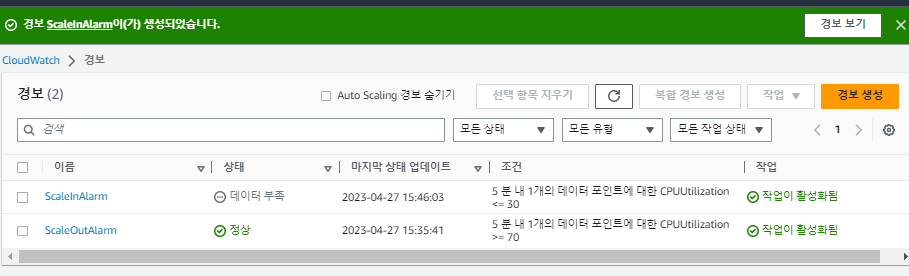
'Cloud Watch 경보'를 새로 생성한다.
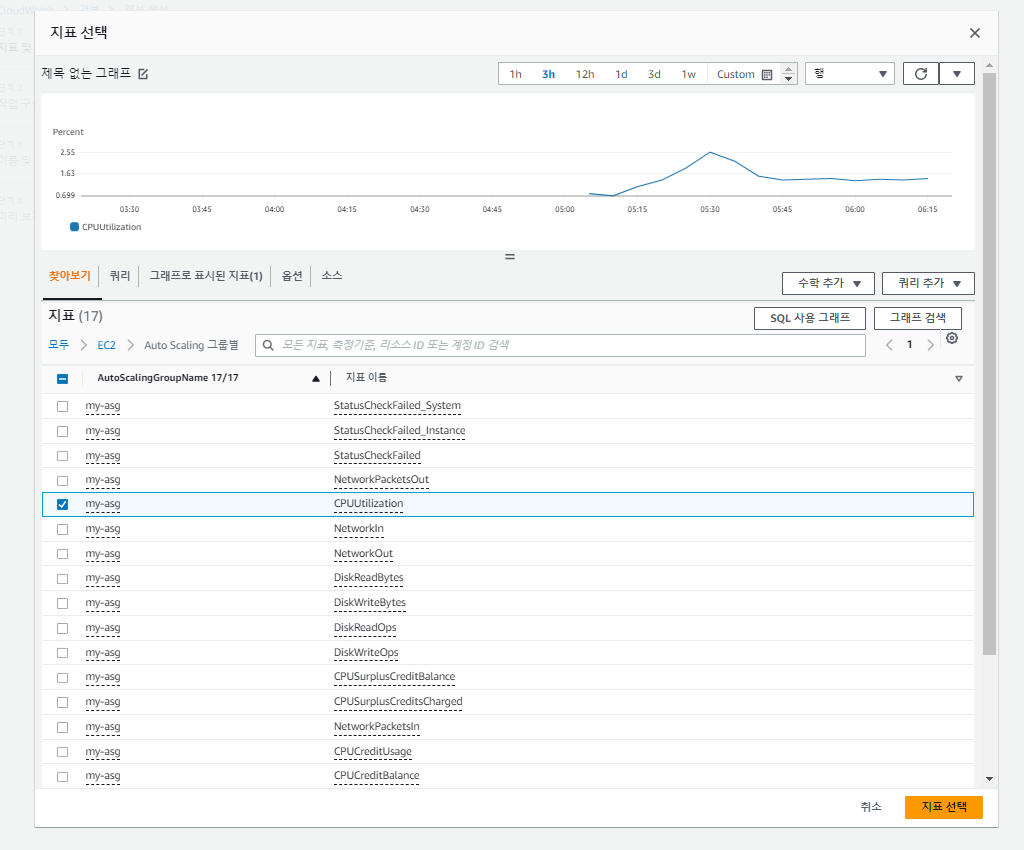
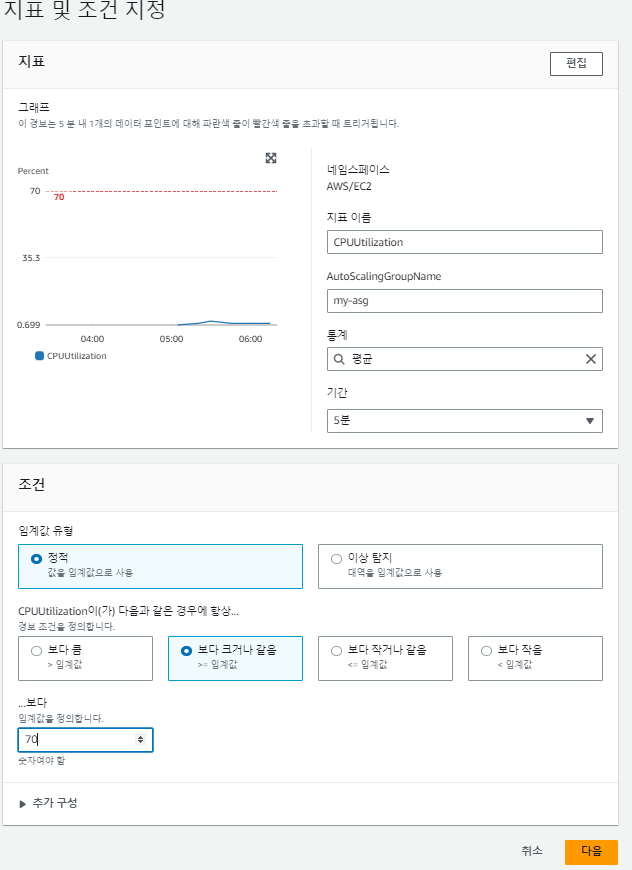
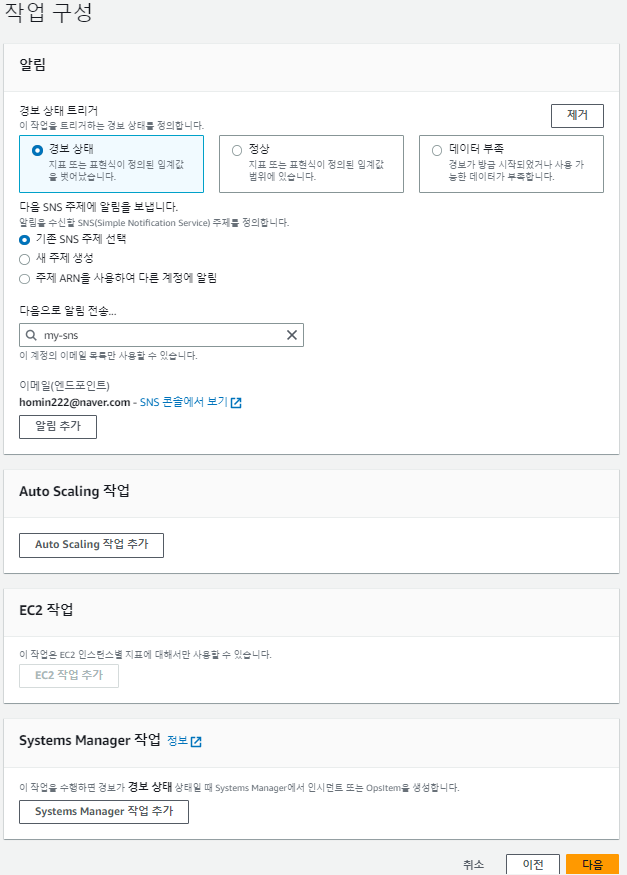
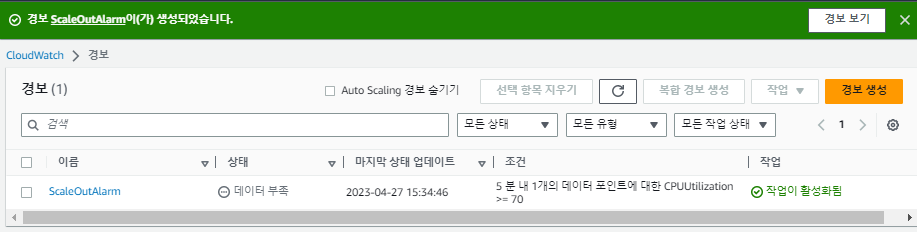
다시 돌아와서,
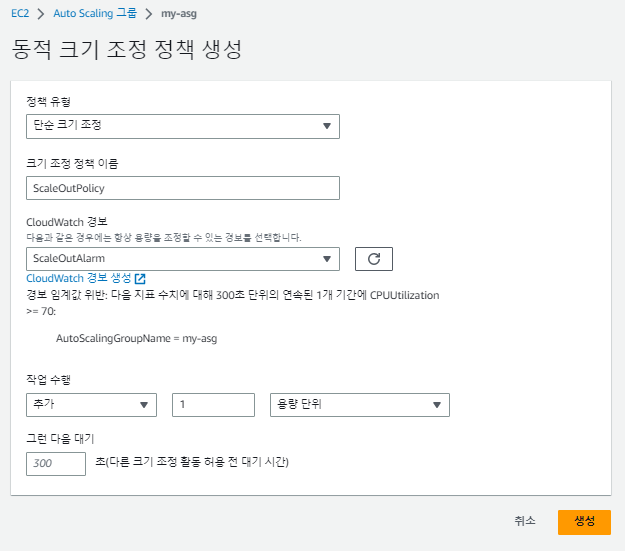
- 단계 크기 조정: 여러 특정 기준에 맞춰 값이 하나 이상 추가 혹은 감소( ex: 70%:1개 추가 / 80%: 2개 추가/ 90%: 3개 추가 / 30%: 1개 제거 / 20%: 2개 제거....)
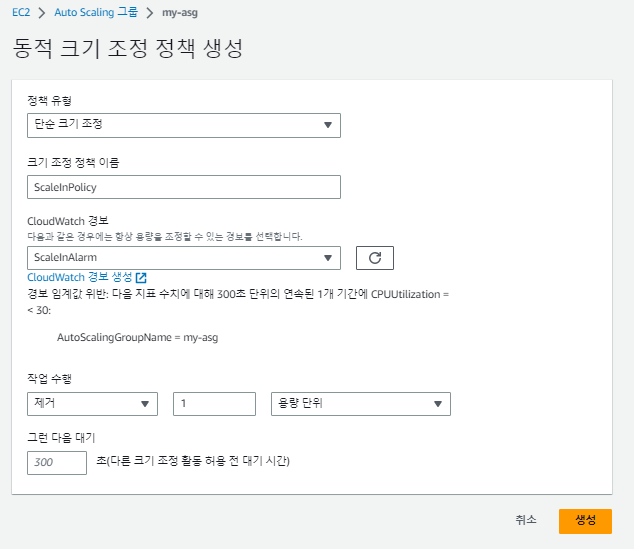
- 단순 크기 조정: 특정 기준에 맞춰 값이 하나씩 늘거나 줄어든다.
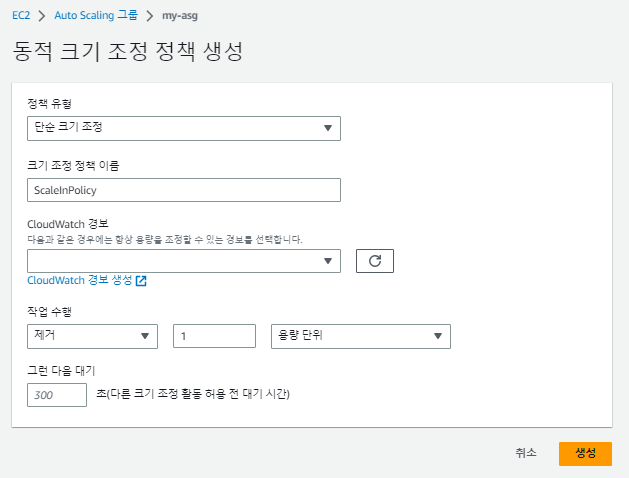
오토 스케일링 (ScaleIn) 생성
이제 CPU 사용률이 감소하면 인스턴스를 줄일 오토 스케일링(ScaleIn)을 생성한다.
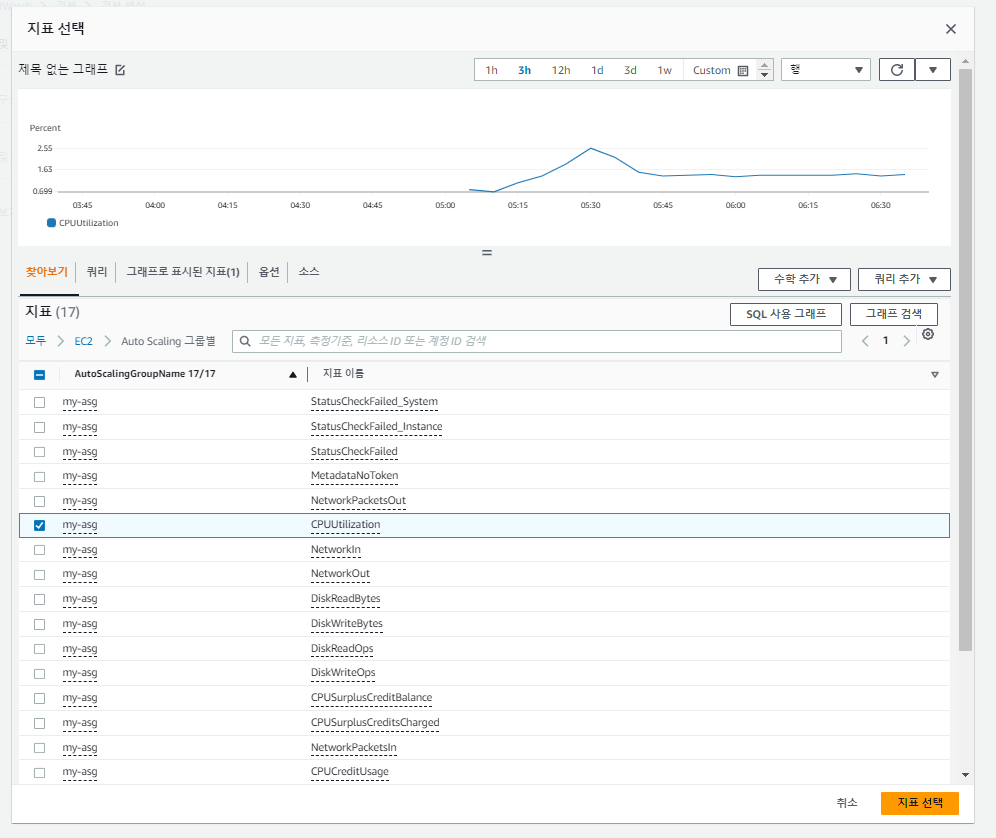
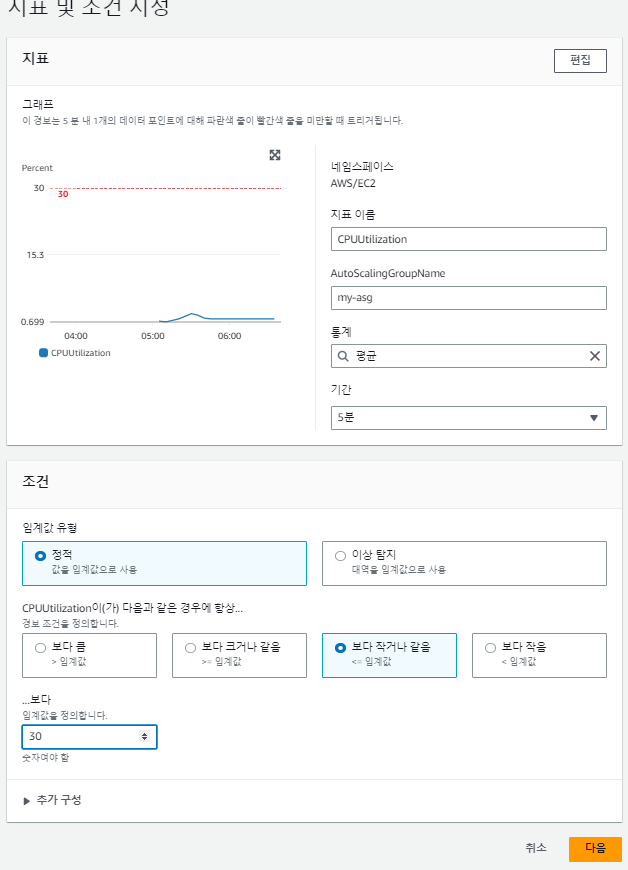
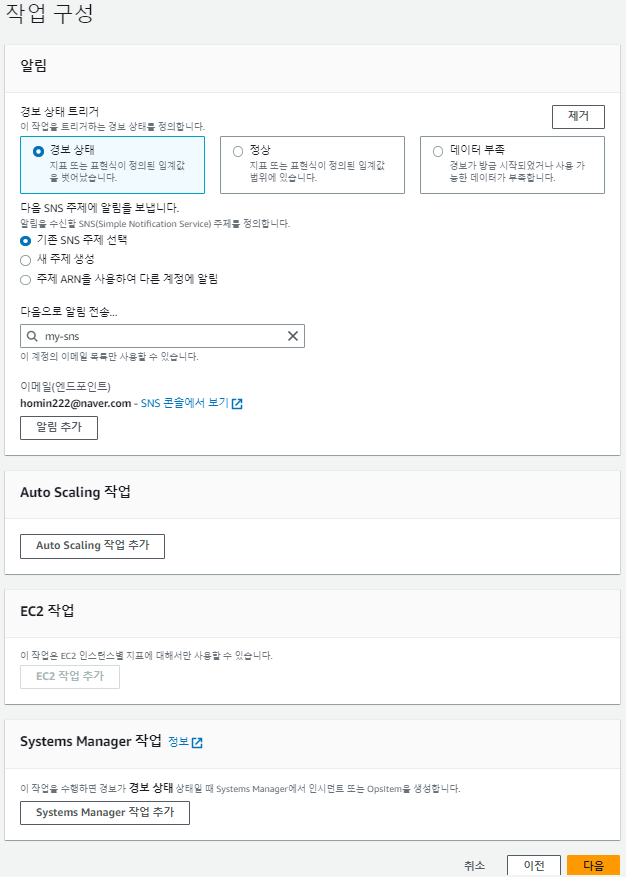
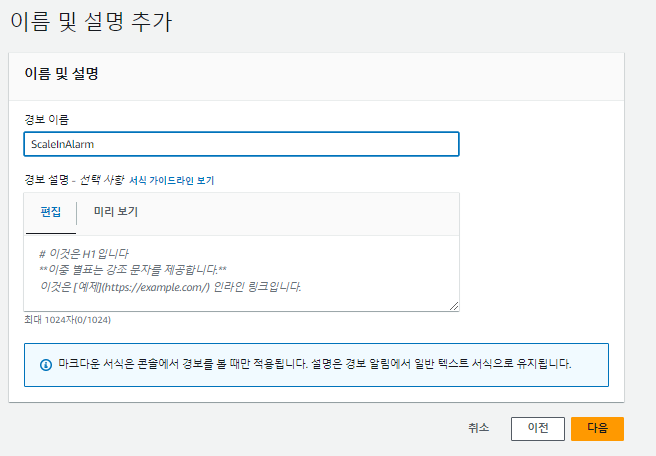

오토 스케일링 테스트
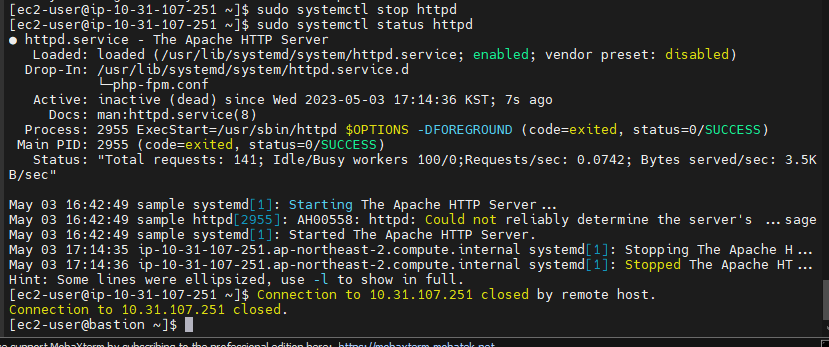
터미널을 이용해 과부화를 줄 예정이다. 그럴려면 터미널로 접근을 해야하므로, 프라이빗에 접근하기 위한 '베스천 호스트'를 생성한다.
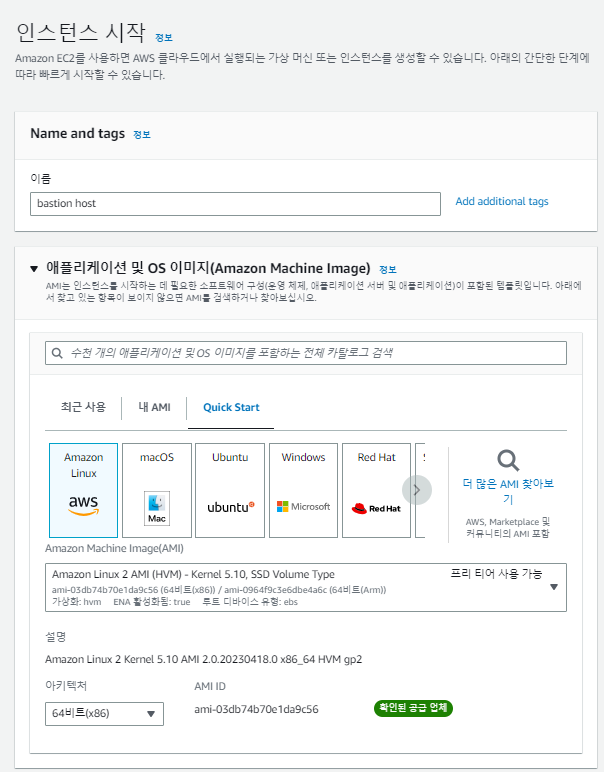
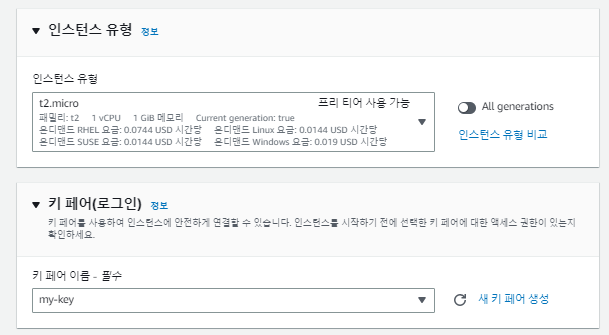
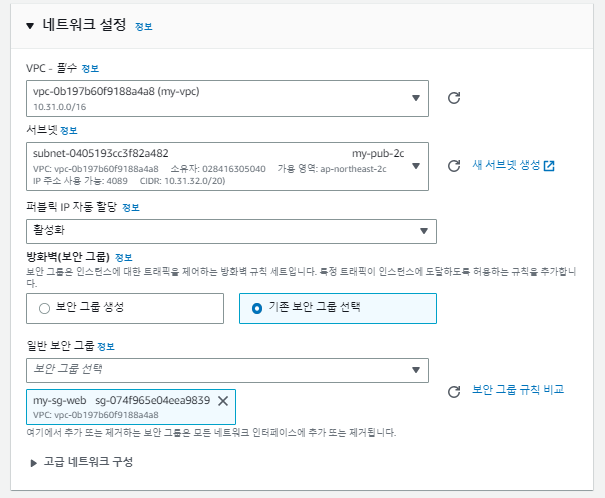
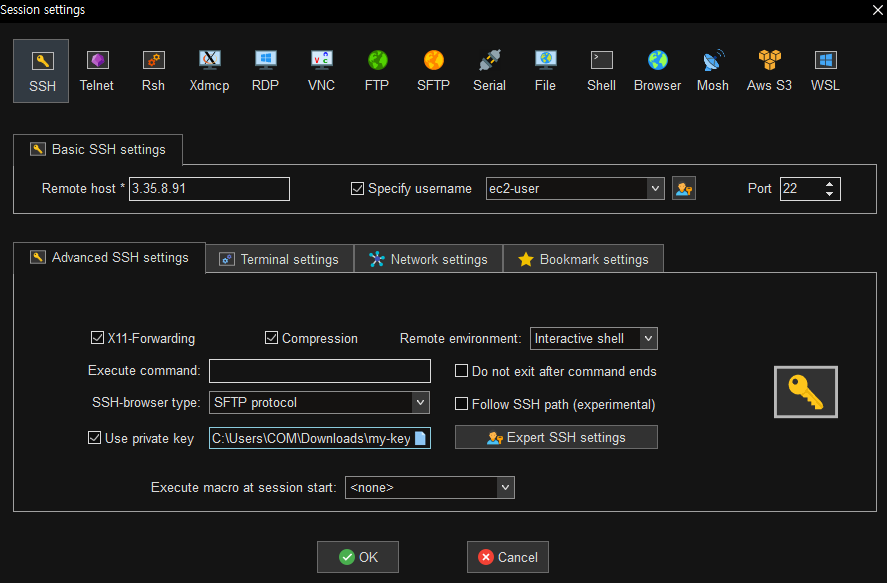
# 키파일의 퍼미션을 400으로 수정 (키 파일은 ReadOnly만 돼야한다.)
sudo chmod 400 my-key.pem# 베스천 호스트를 통해 ssh로 키 인증 방식 접속
ssh -i my-key.pem ec2-user@[asg01/02의 프라이빗 주소]
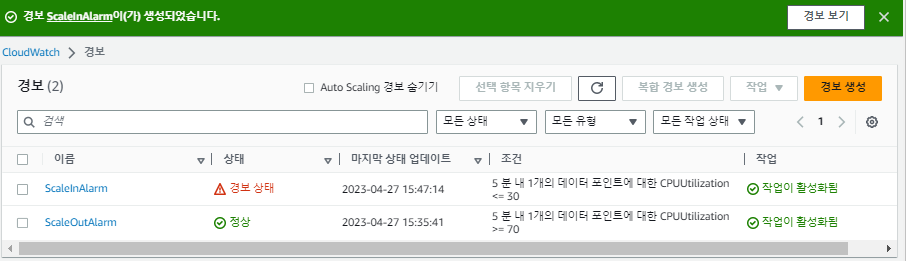
접속에 성공했으니, 이제 본격적으로 부하를 줘서 일부러 경보를 울릴 것이다.
# 'yes'라는 커맨드를 실행해서 그 출력을 '/dev/null' (휴지통과 같은 역할)에 계속 버린다
# 쓸데없는 행위지만, 이러한 반복으로 인해 CPU 사용량이 증가한다. (두 서버에 다 쳐주자)
sudo yes > /dev/null &
# 'top'명령어를 통해 CPU 사용률을 실시간으로 볼 수 있다.
top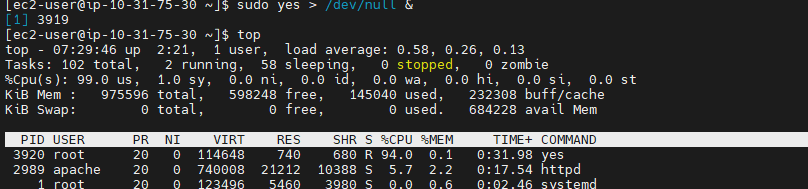

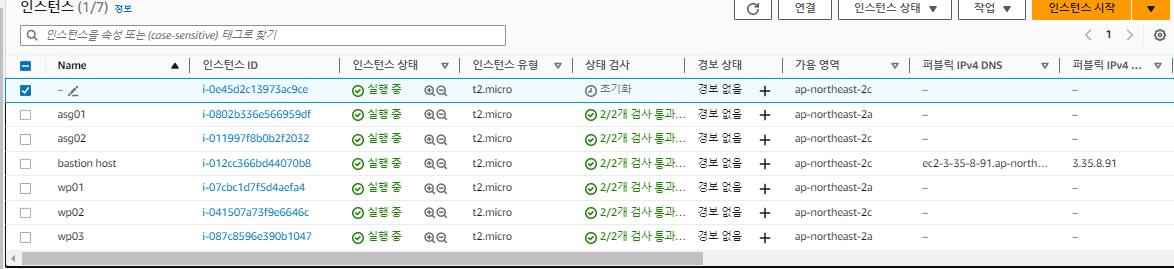
# 'yes'커맨드르 멈춘다.
sudo pkill -9 yes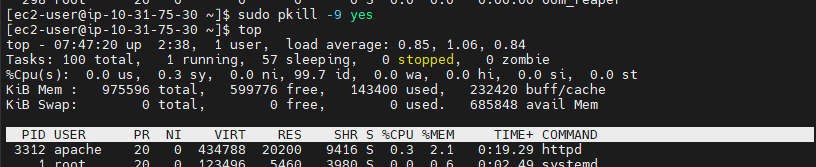

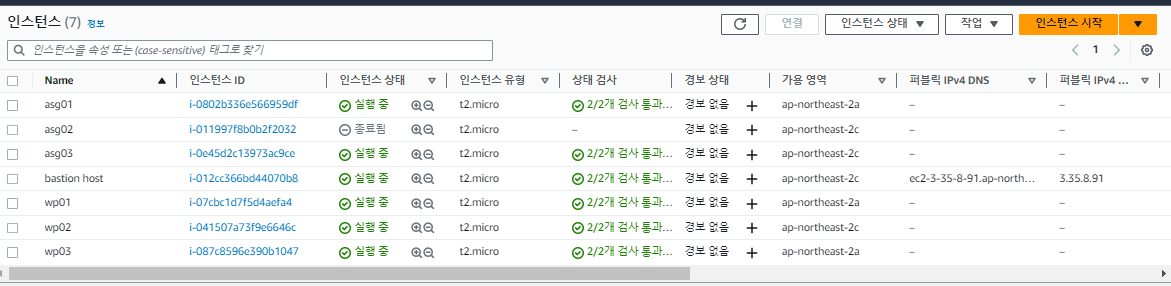
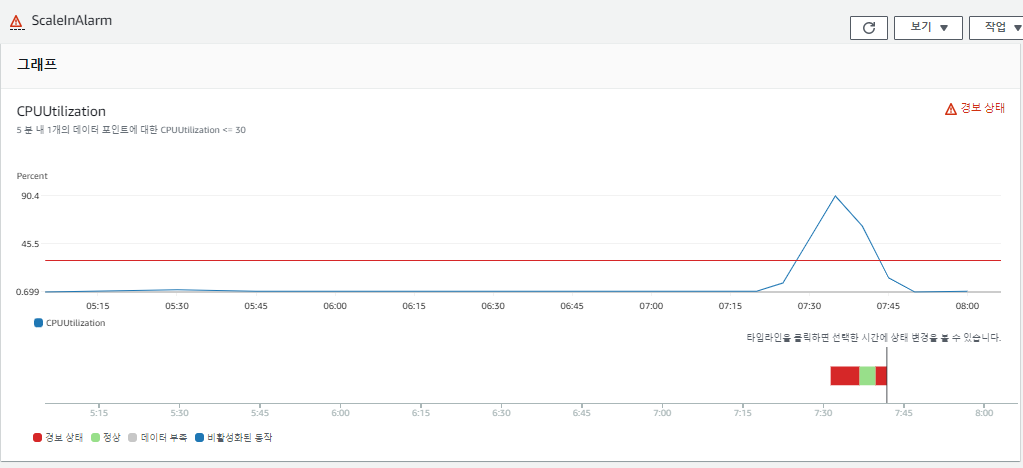
각각의 상황을 그래프로 보면 다음과 같다.
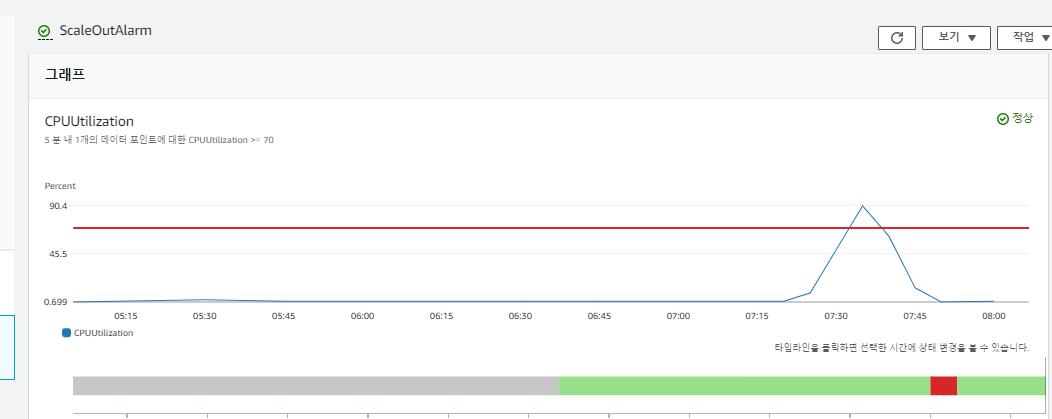
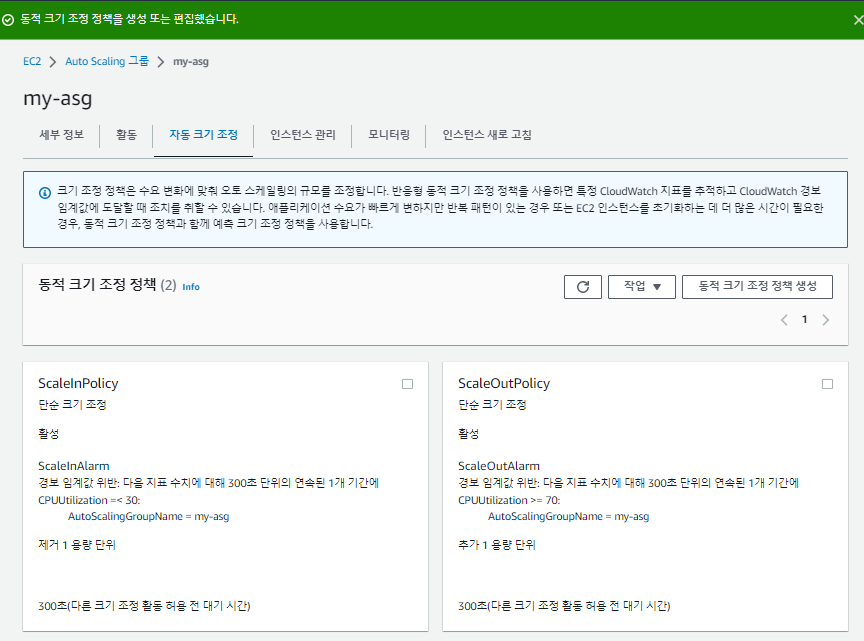
오토 스케일링 그룹의 특징
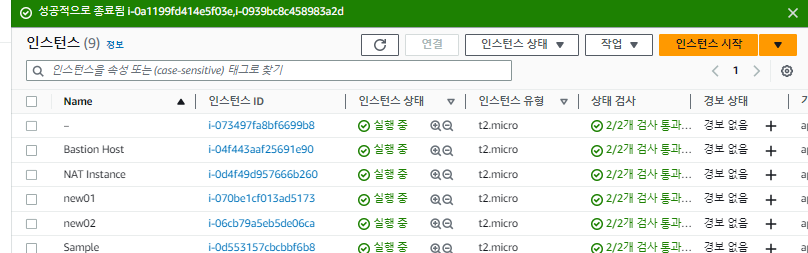
오토 스케일링 그룹은 모든 인스턴스가 종료되더라도 최소 크기를 지키기 위해 자동으로 인스턴스를 다시 재생성한다.
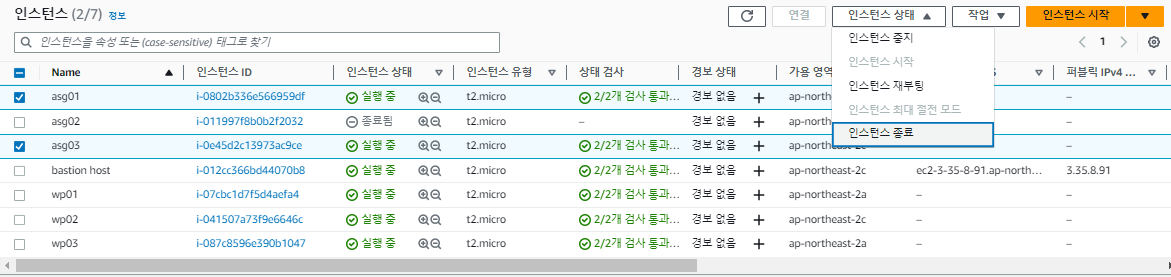
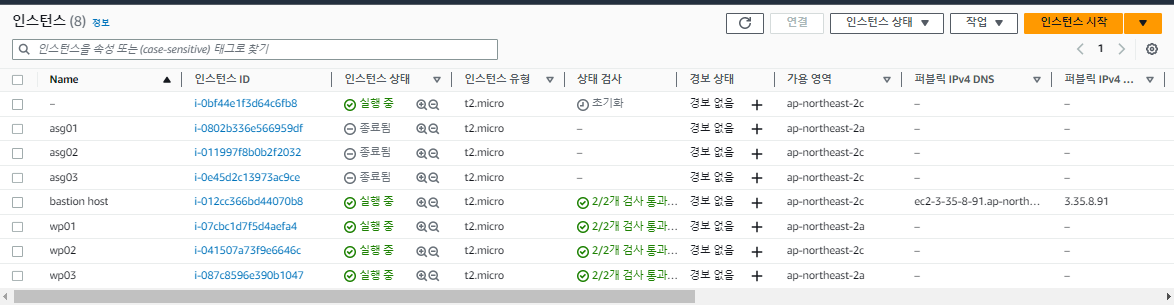
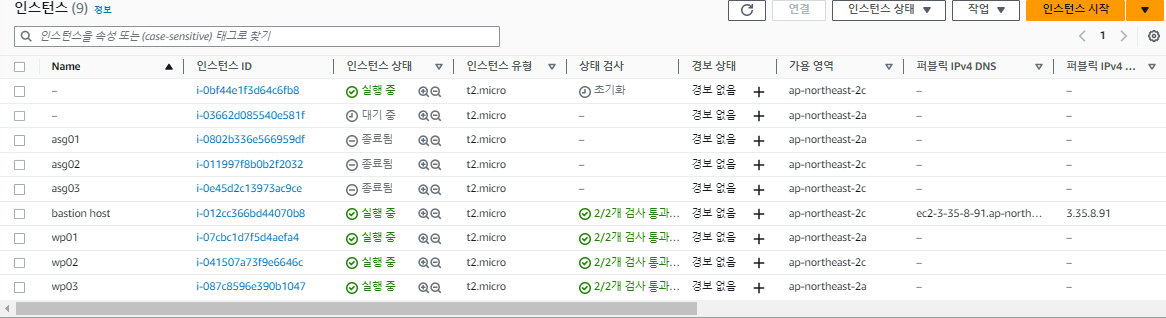
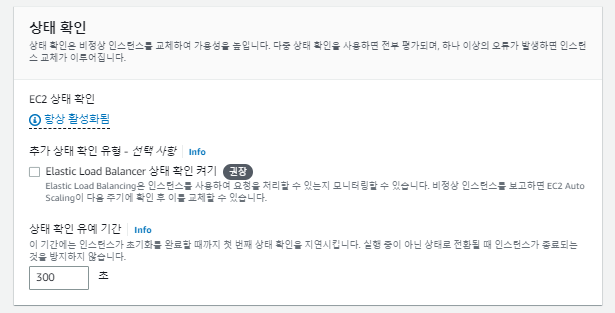
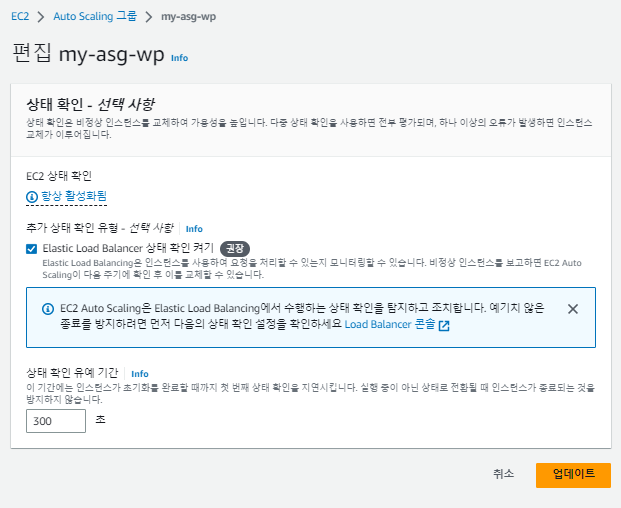
상태 확인에서 Elastic LoadBalancer 상태 확인 켜기
'메가존 클라우드 2기 교육 > AWS' 카테고리의 다른 글
| AWS - 클라우드 보안(공인인증서 발급 및 HTTPS 보안 연결), 아마존 Inspector, CloudWatchLog (0) | 2023.05.02 |
|---|---|
| AWS - CloudFront, Certificate Manager, 클라우드 보안(키 유출 대책) (0) | 2023.05.01 |
| AWS - EFS, NAT 게이트웨이 , S3 (0) | 2023.04.28 |
| AWS - IAM, RDS, ELB(NLB, ALB), Route 53, 워드프레스 (0) | 2023.04.26 |
| AWS - 비용, VPC, EC2, VPC Peering, EBS, EBS Snapshot (0) | 2023.04.25 |



